
How to Control Text-to-Speech Pronunciation Using SSML
Speech synthesis technology has come a long way: instead of robotic sounds, you hear natural sounding speech that rivals a human voice. But the technology is still evolving and isn’t perfect, and the synthesized speech requires some manual tweaking.
The pronunciation of a certain word or sound unit may be different between various languages. For example, in the Japanese word “genba”, the first syllable is pronounced with a hard “g” sound as in “get”, not a soft “g” sound as in “gem”. So, how can you manipulate your Text-to-Speech (TTS) engine to reflect such differences?
Speech Synthesis Markup Language (SSML) is a markup language that provides a standard way to mark up text for the generation of synthetic speech. Using SSML tags to format the text content of a prompt, you can control many aspects of synthetic speech production, such as pronunciation, pitch, pauses, rate of speech, etc. Here’s an example of how a SSML tag can guide pronunciation:
Original written script:
Genba is a Japanese term meaning “the actual place”.
Without SSML tags, here is what the original script sounds like in TTS:
In order for the TTS engine to generate the correct pronunciation, this is the formatted SSML tag and the correct audio:
<speak> <phoneme alphabet="x-sampa" ph="gInbA">Genba</phoneme> is a Japanese term meaning "the actual place". </speak>
As you can see, by inserting a simple tag, the word “genba” is now pronounced correctly.
SSML has many other capabilities when working with TTS. It can add pauses between sentences and/or paragraphs, emphasize certain words, select a speaking voice by attributes, as well as set the pitch, rate, and volume of the speaking voice. Read more about SSML and its features at either the Microsoft or Amazon Speech Platforms.![]()
Using SSML in VideoLocalize
When working on your project in VideoLocalize, you can use SSML formatted text to control various aspects of synthetic speech production very easily.
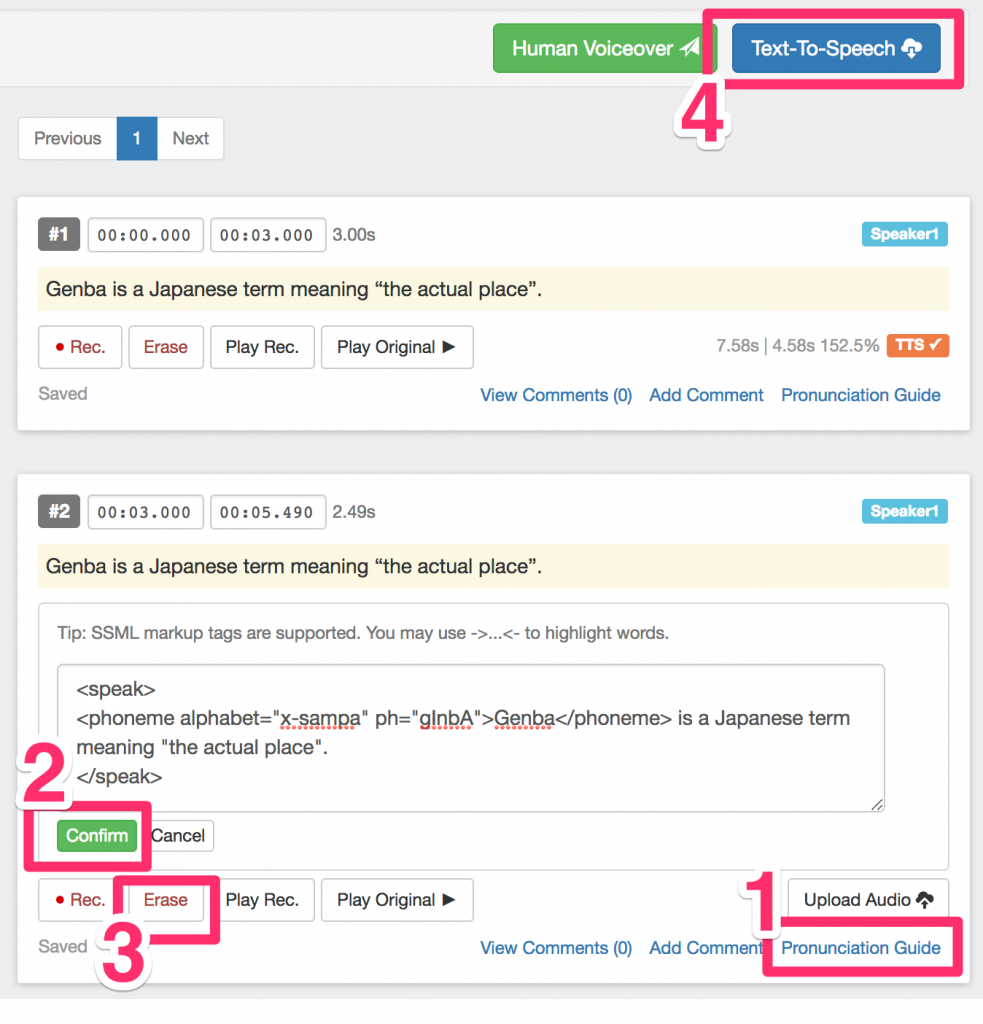
To insert your own SSML tags, take a look at the below sample screen shot and follow these steps:
Step 1: Click on the “Pronunciation Guide” of the segment you want formatted. Once you click on it, a text box will appear beneath the translated Chinese text.
Step 2: Type in your SSML tag, and then click the “Confirm” button.
Step 3: If there was a previous recording of that segment, you should “erase” it first. If there is no previous recording, then just skip Step 3.
Step 4: Generate a new recording by clicking on the “Text-to-Speech” button.
Do you have any questions? Get in touch!